讯飞星火大模型V4.0体验:全面进化_体验不输GPT-4o(飛星體驗模型)
 admin
admin
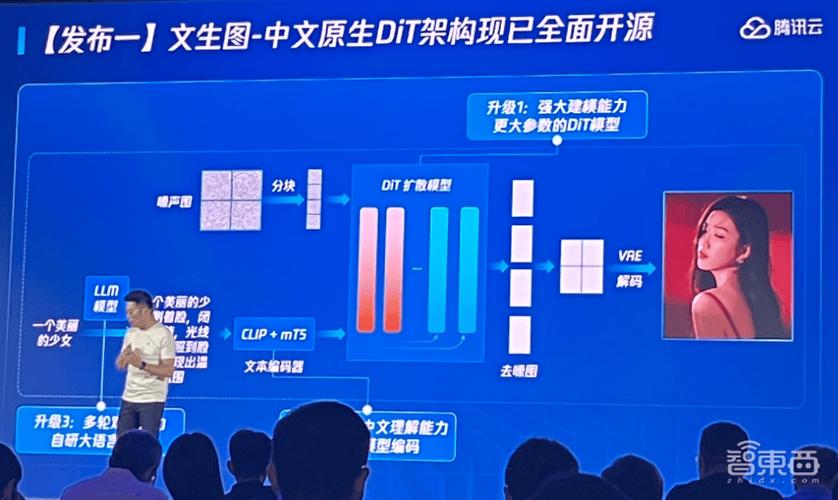
讯飞星火大模型 V4.0 基于全国首个国产万卡算力集群“飞星一号”训练而成,全面提升了大模型底座的七大核心能力。整体超越 GPT-4 Turbo,特别是针对复杂指令、复杂逻辑推理、空间推理、数学、基于逻辑关系的多模理解等方面有着显著的提升。
同时科大讯飞还带来了全新升级的讯飞星火 App / Desk,发布“个人空间”,打造每个人的 AI 助手。
为了进一步了解讯飞星火大模型 V4.0 的实际体验,IT之家也对其做了一番体验评测,今天就为大家送上体验报告。

随着讯飞星火大模型 V4.0 到来,星火 App / Desk 也迎来了功能升级。先以讯飞星火 Desk 为例,进入主界面,可以看到元素更加丰富,左上角多了“创建智能体”的功能入口,左侧栏还有新的“智能体中心”,右侧多了“个人空间”界面。
点击左下角的头像可打开“我的”标签,在底部中间的输入框则可以进行对话。
App 端的界面也有大变化,底部变成了“对话”、“智能体”、“空间”、“个人”四个选项卡,每个选项卡对应的功能界面也各不相同,更加丰富。
1、对话功能
在“对话”功能中,增加了长文本问答的能力,点击对话框右侧的上传文件按钮即可上传文件进行对话。
IT之家上传了一份关于中国通信标准化协会有关扩展现实产业的调查报告,让它帮忙进行摘要,它果然很快就能给出准确的摘要,和文档本身的主要内容也是贴合的。
然后
点击对话界面顶部的返回按钮,就能进入对话列表界面,你创建的对话都能在这里显示,还可以进行置顶或删除。
通过顶部的搜索功能,还可以用关键词搜索相关的智能体、“我的空间”中的文档以及待办事项等信息。
2、智能体
随着生成式 AI 的发展,智能体将成为大模型在应用层面的重要方向。而目前,讯飞星火开放了超过 16000 智能体,覆盖职场、生活、创作等多场景,打造开箱即用的大模型应用。
面向专业垂直场景,讯飞星火 App / Desk 目前首批上线 14 个智能体,包括讯飞晓医、晓知、星火合同助手、讯飞智作、讯飞智文等。
以搭载讯飞星火医疗大模型的“讯飞晓医”为例,它可以为你提供症状自查、药物查询、中医辨证、报告解读、医院和科室推荐以及饮食建议等功能。
比如在报告解读中,
日常生活中,当我们吃药时经常会遇到“不知道这两种药能不能一起吃”的困扰,专门为此去询问医生也比较麻烦,这时就可以用“讯飞晓医”的拍照功能,同时拍下两个药盒,“讯飞晓医”就会结合自身的专业知识来告诉你这两个药是否可以一起吃。
这里
除了拍药品,你还可以将你的体检报告拍照上传,让“讯飞晓医”来帮你分析,比如
不过
再测试一个比较实用的智能体:星火合同助手,它支持合同智审、合同生成、合同比对和合同概要等功能,这里以合同智审为例,
3、个人空间和人设标签功能体验
过去很多时候我们使用 AI 大模型产品输入输出得到的结果都是公开的信息,而对于我们个人的信息,那些公开的大模型就无能为力。但其实无论是学习、工作还是生活,我们往往需要大模型能更懂我们个人的需求,有一个属于我们个人的知识库,全新升级的讯飞星火也考虑到了这一点,特别推出了“个人空间”的功能。
“个人空间”相当于是为用户打造的专属私域知识库,通过上传个人文档,让大模型进行更精确的知识问答和内容生成;并且通过人设标签、日程管理、信息订阅、创建发音人,为用户提供更加个性化和趣味化的服务。
在个人空间里,上传的文档默认会按时间顺序进行排列,你也可以切换到不同文件分类的条目下进行查看。
选择对应的一个或多个文件,你就可以针对这些选中的文件进行翻译、总结、理解、分析或者其他形式的问答,
比如
再比如
另外,在
(1)什么是新能源汽车的“三电”系统。
(2)新能源汽车的“三电”系统各自有什么技术门类?
(3)我国在新能源汽车“三电”系统方面的发展现状。
可以看到,讯飞星火同样很快就给出了一篇小短文,短文语义流畅,要求的内容都包含在内了,结构也比较清晰,不过整体略显程式化,拿来使用的话可以稍做修改。
另外在短文中,讯飞星火 V4.0 还给出了引用来源的标注,某段话来自于资料的那部分,都有来源说明,让文章更加有理有据,减少了大模型幻觉的情况。
除了个人空间,讯飞星火 App / Desk 现在还可以通过人设标签,日程管理、信息订阅、创建发音人等,带来更加个性化和趣味化的服务。
以 App 为例,在“我的”栏目里,现在可以设置自己的人设标签,选定某个人设标签后,大模型会根据你的标签提供个性化的内容和回答。
比如
可以看到,在设定“引经据典,文化内涵”的标签后,讯飞星火输出的短文确实加入了不少名言典故,包括《孟子・告子下》、《论语・阳货》、《论语・述而》等等。
总体来说,全新升级的讯飞星火 App / Desk 功能更强大、更丰富,但在交互布局上并没有显得凌乱,无论是星火 App 还是星火 Desk 各项功能层级都有序、清晰,而且丰富的智能体的加入让讯飞星火更好用、更实用,个人空间以及个性标签等个性化的功能,则让讯飞星火能够成为更懂你的大模型 AI 助手。
二、讯飞星火大模型 V4.0 通用能力体验正如前文所说,本次讯飞星火 V4.0 在通用能力方面全面提升了大模型底座的七大核心能力,特别是针对复杂指令、复杂逻辑推理、空间推理、数学、基于逻辑关系的多模理解等方面有着显著的提升。同时在多模态能力上也得到了再升级。
这里IT之家也针对这些通用能力做了体验测试,测试过程中
而 GPT-4o 目前还不支持视频分析的功能,同样的问题让 GPT-4o 来回答,会出现“无法处理”的信息。
还是针对这段视频,
然后
2、图文能力测试
除了视频理解能力,图文能力也是大家使用大模型比较多的功能。这里IT之家首先考察图片理解能力。
然后再问 GPT-4o,它的回答和讯飞星火 V4.0 差不多,也准确解释了图片的笑点。
接着IT之家用一道几何证明题来考验讯飞星火 V4.0:
上传这张图片,直接让讯飞星火 V4.0 进行解答,可以看到,它给出的答案是正确的,解题的过程也没有什么问题。
再让 GPT-4o 来解答一下这道题,结果就有点奇怪了,虽然最终答案是正确的,但 GPT-4o 输出的内容中有 2/3 都是错误的解题步骤,自我发现后又重新整理思路,最后输出正确答案中所用的中位线定理也是错的。
再看文生图的能力,这也是目前很多人都会用到的功能。
紧接着
再看 GPT-4o,生成的图片也很好看。
还是让它换成中国风的风格,画面整体风格和上一张区别不大,里面多了一些中国风建筑的元素。
3、逻辑推理能力测试
逻辑推理能力是这次讯飞星火 V4.0 的一大升级看点,测试时IT之家也重点考察了讯飞星火 V4.0 在逻辑思维方面的表现。
首先是生活常识推理方面,
1991 年 1 月 25 日至 2024 年 3 月 2 日一共多少天(首尾都算)
讯飞星火 V4.0 给出了详细的演算步骤,
而同样的问题,使用 GPT-4o 来算,它直接给出了答案,也是正确的。
接着
假设有一个池塘,里面有无穷多的水,现有两个空水壶,容积分别是 5 升与 6 升。问如何用这两个水壶从池塘里取得 3 升的水?
对于这个问题讯飞星火 V4.0 的回答步骤清晰,逻辑清楚,实际可操作性也没有问题。
GPT-4o 方面,逻辑思维也挺清楚,实际可操作性也没有问题,不过生成的答案重复,说明的文字较多,步骤也略繁琐些,也算是美中不足吧。
然后
找规律:1=2,2=6,3=12,4=?
对于这个问题,讯飞星火 V4.0 给出了详细的思考步骤,还给出了规律的公式,结果当然也是正确的。
GPT-4o 方面给出的思考步骤和答案也没什么问题:
4、数学能力测试
前面我们测试过两款大模型的逻辑推理能力,与之相似的其实还有数学答题的能力,可以更进一步检测大模型的“智商水平”。测试时,我们直接上今年全国高考卷的真题。
比如这一题:
这是一道函数解析几何的题目,讯飞星火 V4.0 成功做出了回答,
至于 GPT-4o,一顿操作猛如虎,一看答案没算出。
接着看更难一点的单选题最后一题:
讯飞星火 V4.0 给出的答案很简洁,虽然
GPT-4o 这次也给出了正确的答案,不过解题步骤稍显复杂,有些步骤并没有太大的必要。
5、语言理解能力测试
在语言理解能力方面,IT之家主要测试大模型的文本信息抽取能力、情感分析能力、翻译能力和歧义理解能力。
首先文本信息抽取能力方面,我们选择了IT之家此前发布的两篇进行杂糅,让大模型从中提取信息,问题如下:
先看讯飞星火 V4.0 的回答,前两个问题的回答都是准确的,最后一个问题需要绕个弯,讯飞星火 V4.0 已经知道了 5 月和 1-5 月的出口数据,只差相减这一步。
GPT-4o 的回答同样也是前两个问题回答得很准确,但第三个问题直接输出了错误的答案。
接着看情感分析能力,
对于这两个问题,讯飞星火 V4.0 分别给出了答案。IT之家将讯飞星火 V4.0 的回答和标准答案做比对,虽然语言表达上有出入,但整体意思是没问题的,标准答案中需要体现的点讯飞星火 V4.0 在回答中也覆盖到了。
GPT-4o 给出的回答也没什么问题,对文章作者的情感把握也是比较准确的,第二题的回答相对来说也更有条理性一些。
翻译能力方面,IT之家从外媒 tomshardware 找来一段的节选,其中有许多科技专有名词,考验两款大模型的翻译能力:
讯飞星火 V4.0 的翻译整体来说语言通顺流畅,意思也比较清晰明确,其中的专业名词也没有错翻、漏翻。
GPT-4o 这边的翻译效果也很好,和讯飞星火 V4.0 差不多。
最后是语言歧义的理解能力,IT之家找来一句可能产生歧义的句子让大模型去分析:
分析并修改下面这句话中可能产生歧义的问题:
县里的通知说,让赵乡长本月 15 日前去报到。
讯飞星火 V4.0 准确分析出了居中可能存在歧义的原因,在于时间表述不清楚,给出的两种修改方案都可以让句子没有歧义。
GPT-4o 对这句话的歧义问题分析就出现了偏差,修改的结果也不对,有点不知所云。
6、内容生成能力测试
内容生成可能是大家使用大模型最常用的功能,用来辅助我们进行一些文案创作。这里
首先
招聘要求: 有经济学专业背景,有传媒方向工作经验,文笔优秀,能接受经常出差。
招聘待遇: 有五险一金,月薪 15K 起,工作环境新适优雅,节假日还有礼品,一年一次旅行团建。
文案要求: 风格轻松幽默,500 字以内。
讯飞星火 V4.0 给出的文案基本上没有什么扣分点:
GPT-4o 写的文案也很优秀,要求的点都满足了。
上班族们经常会需要写一些方案、活动计划之类的,这时候也可以借助大模型的内容生成能力来帮助自己更快地完成任务。这里IT之家以“我司计划开展一个读书活动,帮我写一个活动方案”为需求,来进行测试。
讯飞星火给出的方案则是比较完整的,时间、地点、目标、流程、前期准备、人员配置、预算评估、结果评估等环节都有,而且不缺细节,可用性很高。
GPT-4o 的计划书相对简洁一些,但也比较完整,该有的地方都有了。
7、代码生成能力测试
用 AI 大模型辅助写代码也是一些程序员常遇到的使用场景,这也可以视为大模型内容生成能力的重要组成。
测试时,
请用 c# 语言生成以下代码:给你一个字符串 s,找到 s 中最长的回文子串。
如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。
代码请遵循以下模板:
public class Solution {
public string LongestPalindrome(string s) {
}
}
我们以代码能直接拿来使用为准则,将大模型生成的代码用程序运行工具进行检测,看是否能直接完美运行。
首先还是看讯飞星火 V4.0,它给出的代码格式标准,算法也比较简洁,看起来很清爽。
由于
GPT-4o 这边,给出的代码同样有规范的格式,也比较简洁.
拿到检测软件中运行,也可以成功运行,表现同样不错。
总体来说,在大模型的通用能力方面,讯飞星火 V4.0 和目前 ChatGPT 最先进的 GPT-4o 模型相比,从
在发布会上,科大讯飞还谈到了讯飞星火大模型在国家能源集团、中国石油、中国移动、中国人保、太平洋保险、交通银行等重点行业的应用,可见讯飞星火已经在 AI 大模型领域构建起自主可控的独特优势,而通过对讯飞星火 V4.0 的体验,IT之家也对讯飞星火未来在 AI 领域的表现充满期待,相信他们能够持续进化,让国产 AI 大模型技术和应用生态真正实现国际化的引领。