V8工作原理(回收垃圾編譯)
 admin
admin
(Number\String\Boolean\undefined\null\BigInt\Symbol)和1种引用类型(Object)。原始类型的赋值会完整的赋值变量值,引用类型的赋值是复制引用地址。
JavaScript 的内存模型分为三种:代码空间、栈空间、堆空间。
栈空间和堆空间原始类型的数据存放在栈中,引用类型存在堆中。堆中的数据是通过引用和变量关联起来的,JavaScript 的变量没有数据类型,值才有数据类型,变量可以持有任何数据类型的数据。
堆空间存储
为什么引用数据类型放在堆空间?因为该类型数据占用的空间往往比较大,如果放在栈中,会影响到调用栈的执行上下文的切换效率,也可能导致栈空间不足;而堆空间比较大,能存放很多大的数据。
垃圾回收机制程序中,有些数据在使用之后,我们不再需要了,这种数据就称为垃圾数据。只有回收了垃圾数据,才能释放内存空间,无法回收或回收不及时的情况,我们就称为内存泄漏。
JavaScript 的垃圾是由垃圾回收器自动回收的。数据存放在“栈空间”和“堆空间”,那垃圾回收器是如何回收的呢?
调用栈中的数据是如何回收的调用栈在入栈时存储上下文数据,当某上下文执行完成出栈(pop stack) 后,就销毁掉了执行上下文,相应的内存空间就会被回收。
调用栈中通过记录当前执行状态的指针(称为 ESP)下移操作,来销毁执行完毕的函数存在栈中的执行上下文的过程。
堆中的数据是如何回收的回收堆中的垃圾数据,如要利用 JavaScript 的垃圾回收器。
代际假说和分代收集代际假说(The Generational Hypothesis)
第一个是大部分对象在内存中存在的时间很短,就是很多对象一经过分配内存,很快就变得不可访问。第二个是不死的对象,会活得更久。V8 中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象。新生代区通常只支持 1~8M 的容量,老生代区则容量大很多。这两块区域,V8分别使用了不同的垃圾回收器,以便更高效的实施垃圾回收。
副垃圾回收器,主要负责新生代的垃圾回收。主垃圾回收器,主要负责老生代的垃圾回收。垃圾回收器的工作流程1、标记空间汇总活动对象和非活动对象2、回收非活动对象所占据的内存3、内存整理副垃圾回收器使用 Scavenge 算法 结合 对象晋升策略。
主垃圾回收器使用 标记-清除(Mark-Sweep)算法进行垃圾回收,然后使用标记-整理(Mark-Compact) 进行内存整理。
全停顿由于垃圾回收器是运行在 JavaScript 主线程上的,单线程的原因,执行垃圾回收算法的时候使得 JavaScript 脚本执行暂停,导致性能下降。为了解决这个问题,V8 将垃圾回收中的标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,知道标记阶段完成(增量标记 Incremental Marking 算法)。
编译器和解析器编译型语言 在执行程序之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件,这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。比如 C/C++、GO、Java等。
解释型语言 在每次运行时都需要通过解释器对程序进行动态的解释和执行。比如 Python、JavaScript。
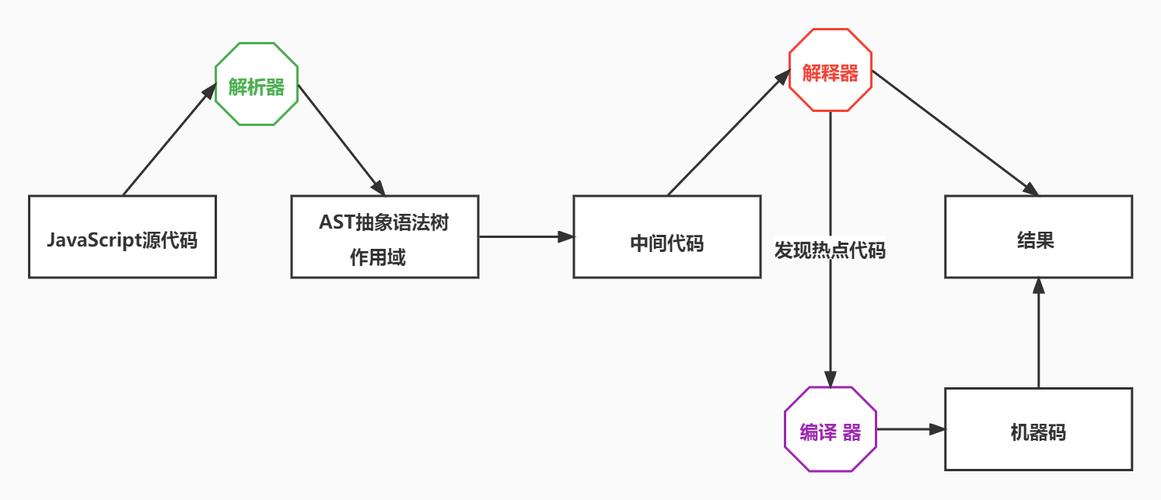
JS 代码编译解析执行过程
V8 依据 JavaScript 代码生成 AST 和执行上下文,再基于 AST 生成字节码(编译),然后通过解释器执行字节码,通过编译器来优化编译字节码。
JavaScript 中编译面向的是全局代码或函数,比如下载完一个js文件,先编译这个js文件,但是js文件内定义的函数是不会编译的,等调用到该函数的时候,JavaScript 引擎才会去编译该函数。
可以吧 JavaScript 的编译看成部分:
第一部分从一段 JavaScript 代码编译到字节码,然后解释器解释执行字节码;第二部分深度编译,将活跃的字节码编译成二进制,然后直接执行二进制。本文来自:《浏览器的工作原理与实践》极客时间-李兵 的学习笔记记录